अध्याय 8 संरचित क्वेरी भाषा (SQL) का परिचय
“रिलेशनल मॉडल पर हुए अनुसंधान कार्य के पीछे सबसे महत्वपूर्ण प्रेरणा यह उद्देश्य था कि डेटाबेस प्रबंधन के तार्किक और भौतिक पहलुओं के बीच एक स्पष्ट और तीव्र सीमा निर्धारित की जा सके।”
– ई. एफ. कॉड
8.1 परिचय
हमने पिछले अध्याय में रिलेशनल डेटाबेस प्रबंधन प्रणाली (RDBMS) और उसके उद्देश्य के बारे में सीखा है। कई RDBMS जैसे MySQL, Microsoft SQL Server, PostgreSQL, Oracle आदि हैं जो हमें ऐसा डेटाबेस बनाने की अनुमति देते हैं जिसमें संबंध (relations) होते हैं और एक या अधिक संबंधों को कुशलतापूर्वक पूछताछ (querying) के लिए जोड़ा जा सकता है ताकि डेटा को संग्रहीत, पुनः प्राप्त और उसमें हेरफेर किया जा सके। इस अध्याय में हम सीखेंगे कि MySQL का उपयोग करके डेटाबेस कैसे बनाया जाए, उसे डेटा से भरा जाए और उस पर पूछताछ की जाए।
8.2 स्ट्रक्चर्ड क्वेरी लैंग्वेज (SQL)
फ़ाइल सिस्टम के मामले में डेटा तक पहुँचने के लिए एप्लिकेशन प्रोग्राम लिखने पड़ते हैं। हालाँकि, डेटाबेस प्रबंधन प्रणालियों के लिए विशेष प्रकार की प्रोग्रामिंग भाषाएँ होती हैं जिन्हें क्वेरी लैंग्वेज कहा जाता है जिनका उपयोग डेटाबेस से डेटा तक पहुँचने के लिए किया जा सकता है। स्ट्रक्चर्ड क्वेरी लैंग्वेज (SQL) सबसे लोकप्रिय क्वेरी लैंग्वेज है जिसका उपयोग प्रमुख रिलेशनल डेटाबेस प्रबंधन प्रणालियों जैसे MySQL, ORACLE, SQL Server आदि द्वारा किया जाता है।
SQL सीखना आसान है क्योंकि इसके कथनों में वर्णनात्मक अंग्रेज़ी शब्द होते हैं और यह केस-सेंसिटिव नहीं है। हम SQL का उपयोग करके एक डेटाबेस को कुशल और आसान तरीके से बना सकते हैं और उससे संवाद कर सकते हैं। SQL का लाभ यह है कि हमें यह निर्दिष्ट नहीं करना पड़ता कि डेटाबेस से डेटा कैसे प्राप्त करना है। बल्कि, हम केवल यह बताते हैं कि क्या निकालना है, और बाकी SQL खुद कर देता है। यद्यपि इसे क्वेरी भाषा कहा जाता है, SQL केवल क्वेरी करने से कहीं अधिक कर सकता है। SQL डेटा की संरचना को परिभाषित करने, डेटाबेस में डेटा को संचालित करने, बाधाएँ घोषित करने और हमारी आवश्यकताओं के अनुसार विभिन्न तरीकों से डेटाबेस से डेटा पुनः प्राप्त करने के लिए कथन प्रदान करता है।
इस अध्याय में हम सीखेंगे कि MySQL को RDBMS सॉफ़्टवेयर के रूप में उपयोग करके एक डेटाबेस कैसे बनाया जाता है। हम एक डेटाबेस बनाएँगे जिसे Student Attendance (चित्र 7.5) कहा जाता है, जिसे हमने पिछले अध्याय में पहचाना था। हम यह भी सीखेंगे कि डेटाबेस को डेटा से कैसे भरा जाता है, उसमें डेटा को कैसे संचालित किया जाता है और SQL क्वेरीज़ के माध्यम से डेटाबेस से डेटा कैसे प्राप्त किया जाता है।
8.2.1 MySQL इंस्टॉल करना
MySQL एक ओपन सोर्स RDBMS सॉफ़्टवेयर है जिसे आधिकारिक वेबसाइट https://dev.mysql.com/downloads से आसानी से डाउनलोड किया जा सकता है। MySQL इंस्टॉल करने के बाद, MySQL सेवा प्रारंभ करें। mysql> प्रॉम्प्ट (चित्र 8.1) का प्रदर्शन इस बात का संकेत है कि MySQL हमारे लिए SQL कथन दर्ज करने के लिए तैयार है।
MySQL में SQL कथन लिखते समय कुछ नियमों का पालन करना होता है
गतिविधि 8.1
LibreOffice Base का अन्वेषण करें और इसकी तुलना MySQL से करें:
- SQL केस-संवेदनहीन है। इसका मतलब है कि name और NAME SQL के लिए एक ही हैं।
- हमेशा SQL कथन को अर्धविराम (;) से समाप्त करें।
- बहु-पंक्ति SQL कथन दर्ज करने के लिए, हम पहली पंक्ति के बाद ‘;’ नहीं लिखते। हम अगली पंक्ति पर जारी रखने के लिए Enter दबाते हैं। तब संकेत mysql> ‘->’ में बदल जाता है, जो दर्शाता है कि कथन अगली पंक्ति तक जारी है। अंतिम पंक्ति के बाद ‘;’ डालें और Enter दबाएं।
8.3 MySQL में डेटा प्रकार और बाधाएँ
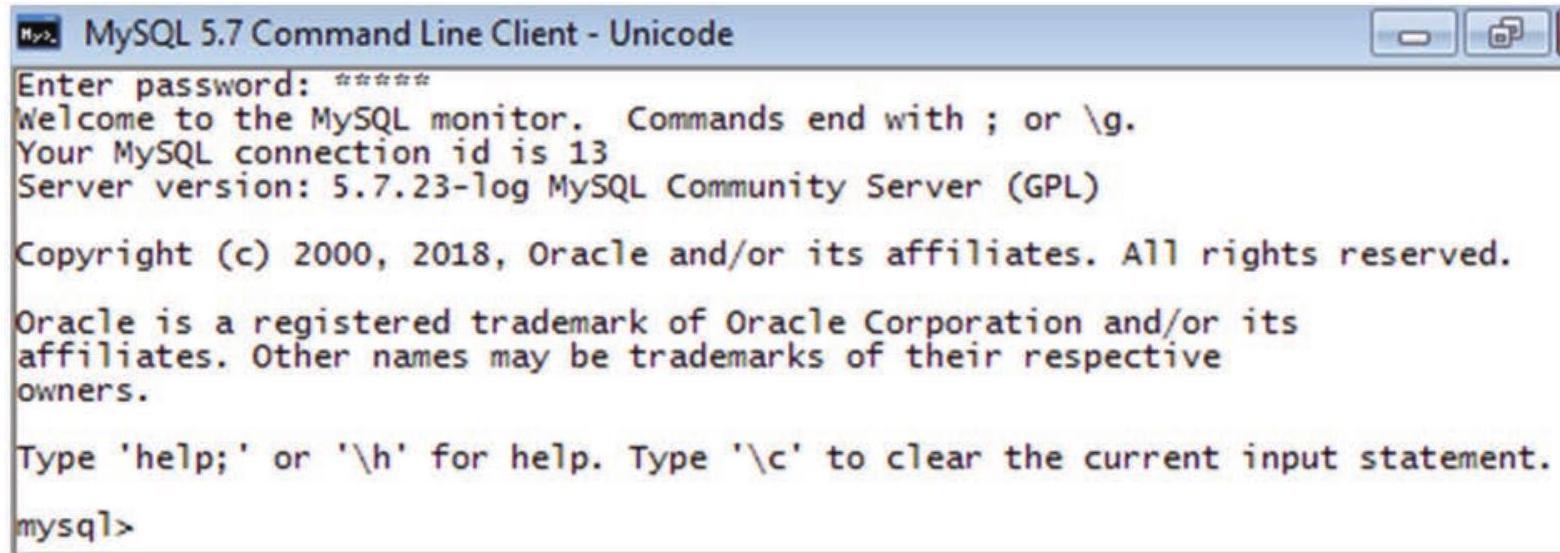
आकृति 8.1: MySQL शैल
हम जानते हैं कि एक डेटाबेस एक या अधिक संबंधों से बना होता है और प्रत्येक संबंध (तालिका) गुणों (स्तंभ) से बनी होती है। प्रत्येक गुण का एक डेटा प्रकार होता है। हम संबंध के प्रत्येक गुण के लिए बाधाएँ भी निर्दिष्ट कर सकते हैं।
क्रियाकलाप 8.2
MySQL में समर्थित अन्य डेटा प्रकार कौन-से हैं? क्या पूर्णांक और फ्लोट डेटा प्रकार के अन्य रूप भी हैं?
8.3.1 गुण का डेटा प्रकार
डेटा प्रकार दर्शाता है कि एक गुण किस प्रकार के डेटा मान रख सकता है। गुण का डेटा प्रकार यह तय करता है कि उस गुण के डेटा पर कौन-से संचालन किए जा सकते हैं। उदाहरण के लिए, संख्यात्मक डेटा पर अंकगणितीय संचालन किए जा सकते हैं, परंतु वर्ण डेटा पर नहीं। MySQL में प्रायः प्रयुक्त डेटा प्रकार संख्यात्मक प्रकार, दिनांक और समय प्रकार, और स्ट्रिंग (वर्ण और बाइट) प्रकार हैं, जैसा कि तालिका 8.1 में दिखाया गया है।
सोचिए और विचार कीजिए
क्या आप ऐसा कोई गुणधर्म सोच सकते हैं जिसके लिए निश्चित लंबाई वाला स्ट्रिंग उपयुक्त हो?
Table 8.1 MySQL में प्रायः प्रयुक्त डेटा प्रकार
| डेटा प्रकार | विवरण |
|---|---|
| CHAR $(n)$ | लंबाई $\mathrm{n}$ वाले वर्ण प्रकार के डेटा को निर्दिष्ट करता है, जहाँ $\mathrm{n}$ 0 से 255 तक कोई भी मान हो सकता है। CHAR निश्चित लंबाई वाला होता है, अर्थात् CHAR (10) घोषित करने से 10 वर्णों के लिए स्थान आरक्षित होता है। यदि डेटा में 10 वर्ण नहीं हैं (उदाहरण के लिए, ‘city’ में चार वर्ण हैं), तो MySQL शेष 6 वर्णों को दाहिनी ओर स्पेस भरकर पूरा करता है। |
| VARCHAR( $n)$ | लंबाई ‘$n$’ वाले वर्ण प्रकार के डेटा को निर्दिष्ट करता है, जहाँ $\mathrm{n}$ 0 से 65535 तक कोई भी मान हो सकता है। लेकिन CHAR के विपरीत, VARCHAR परिवर्तनीय-लंबाई वाला डेटा प्रकार है। अर्थात्, VARCHAR (30) घोषित करने से अधिकतम 30 वर्ण संग्रहीत किए जा सकते हैं, लेकिन वास्तविक आवंटित बाइट्स दर्ज किए गए स्ट्रिंग की लंबाई पर निर्भर करेंगे। इसलिए VARCHAR (30) में ‘city’ केवल 4 वर्ण संग्रहीत करने के लिए आवश्यक स्थान घेरेगा। |
| INT | INT एक पूर्णांक मान निर्दिष्ट करता है। प्रत्येक INT मान 4 बाइट्स संग्रहण घेरता है। पूर्णांक प्रकार में अनुमत मानों की सीमा -2147483648 है; उससे बड़े मानों के लिए हमें BIGINT का उपयोग करना होता है, जो 8 बाइट्स घेरता है। |
| FLOAT | दशमलव बिंदु वाली संख्याएँ रखता है। प्रत्येक FLOAT मान 4 बाइट्स घेरता है। |
| DATE | DATE प्रकार ‘YYYY-MM-DD’ प्रारूप में तिथियों के लिए प्रयुक्त होता है। YYYY 4 अंकों का वर्ष है, MM 2 अंकों का माह है और DD 2 अंकों की तिथि है। समर्थित सीमा ‘1000-01-01’ से ‘9999-12-31’ तक है। |
सोचिए और विचार कीजिए
कौन-से दो constraints मिलकर Primary Key constraint उत्पन्न करते हैं?
8.3.2 Constraints
Constraints कुछ विशेष प्रकार की प्रतिबंधित शर्तें होती हैं जो किसी attribute में आने वाले डेटा मानों पर लगाई जाती हैं। इनका उपयोग डेटा की शुद्धता और विश्वसनीयता सुनिश्चित करने के लिए किया जाता है। यद्यपि किसी table के प्रत्येक attribute के लिए constraint परिभाषित करना अनिवार्य नहीं है। Table 8.2 विभिन्न SQL constraints की सूची देता है।
Table 8.2 प्राय: प्रयुक्त SQL Constraints
| Constraint | विवरण |
|---|---|
| NOT NULL | यह सुनिश्चित करता है कि किसी column में NULL मान न आए, जहाँ NULL का अर्थ है लुप्त/अज्ञात/अप्रयोज्य मान। |
| UNIQUE | यह सुनिश्चित करता है कि column के सभी मान अद्वितीय/विशिष्ट हों। |
| DEFAULT | यदि कोई मान प्रदान न किया जाए तो column के लिए निर्धारित एक पूर्वनिर्धारित मान। |
| PRIMARY KEY | वह column जो table की प्रत्येक row या record को अद्वितिय रूप से पहचान सकता है। |
| FOREIGN KEY | वह column जो किसी अन्य table में PRIMARY KEY के रूप में परिभाषित attribute के मान को संदर्भित करता है। |
8.4 SQL for Data Definition
SQL relation schemas को परिभाषित करने, उन्हें संशोधित करने और relations को हटाने के लिए आदेश प्रदान करता है। इन्हें Data Definition Language (DDL) कहा जाता है जिसके माध्यम से relations का समुच्च निर्दिष्ट किया जाता है, जिसमें उनका schema, प्रत्येक attribute के लिए डेटा प्रकार, constraints के साथ-साथ सुरक्षा और पहुँच-संबंधी अधिकार भी शामिल होते हैं।
डेटा परिभाषा CREATE कथन से शुरू होती है। यह कथन डेटाबेस और उसकी तालिकाओं (संबंधों) को बनाने के लिए प्रयोग किया जाता है। डेटाबेस बनाने से पहले, हमें यह स्पष्ट होना चाहिए कि डेटाबेस में कितनी तालिकाएँ होंगी, प्रत्येक तालिका में कौन-कौन स्तंभ (गुण) होंगे और प्रत्येक स्तंभ का डेटा प्रकार क्या होगा। इसी प्रकार हम संबंध स्कीमा तय करते हैं।
8.4.1 CREATE Database
डेटाबेस बनाने के लिए, हम CREATE DATABASE कथन का उपयोग करते हैं जैसा कि निम्नलिखित सिंटैक्स में दिखाया गया है:
Student Attendance नामक डेटाबेस बनाने के लिए, हम mysql प्रॉम्प्ट पर निम्नलिखित कमांड टाइप करेंगे।
mysql> CREATE DATABASE Studentattendance;
Query OK, 1 row affected $(0.02 \mathrm{sec})$
नोट: LINUX वातावरण में, डेटाबेस और तालिकाओं के नाम केस-संवेदी होते हैं जबकि WINDOWS में ऐसा कोई भेद नहीं होता। हालाँकि, एक अच्छा अभ्यास यह है कि डेटाबेस या तालिका का नाम उसी अक्षर केस में लिखा जाए जो उनकी रचना के समय प्रयोग किया गया था।
एक DBMS एक कंप्यूटर पर कई डेटाबेस प्रबंधित कर सकता है। इसलिए, हमें उस डेटाबेस का चयन करना होता है जिसे हम प्रयोग करना चाहते हैं। एक बार डेटाबेस चयनित हो जाने के बाद, हम तालिकाएँ बनाने या डेटा क्वेरी करने के लिए आगे बढ़ सकते हैं। डेटाबेस का उपयोग करने के लिए निम्नलिखित SQL कथन लिखें:
mysql> USE StudentAttendance;
Database changed
प्रारंभ में, बनाया गया डेटाबेस खाली होता है। इसे show tables कमांड का उपयोग करके जाँचा जा सकता है जो डेटाबेस के भीतर सभी तालिकाओं के नाम सूचीबद्ध करता है।
mysql> SHOW TABLES;
Empty set (0.06 sec)
गतिविधि 8.3
कथन show database; टाइप करें। क्या यह Student Attendance डेटाबेस का नाम दिखाता है?
8.4.2 CREATE Table
StudentAttendance डेटाबेस बनाने के बाद, हमें इस डेटाबेस में संबंधों (tables) को परिभाषित करना होता है और प्रत्येक संबंध के लिए attributes निर्दिष्ट करने होते हैं साथ ही प्रत्येक attribute के लिए data types। यह CREATE TABLE कथन का उपयोग करके किया जाता है।
Syntax:
CREATE TABLE tablename(
attributename1 datatype constraint,
attributename2 datatype constraint,
:
attributenameN datatype constraint);
Create Table कथन के संबंध में निम्नलिखित बिंदुओं का ध्यान रखना महत्वपूर्ण है:
- $\mathrm{N}$ संबंध की डिग्री है, इसका अर्थ है table में $\mathrm{N}$ कॉलम हैं।
- Attribute name table में कॉलम का नाम निर्दिष्ट करता है।
- Datatype यह निर्दिष्ट करता है कि कोई attribute किस प्रकार का data रख सकता है।
- Constraint किसी attribute के मानों पर लगाए गए प्रतिबंधों को इंगित करता है। डिफ़ॉल्ट रूप से, प्रत्येक attribute NULL मान ले सकता है, primary key को छोड़कर।
आइए तालिका STUDENT के गुणों के डेटा प्रकारों को उनके प्रतिबंधों सहित पहचानें। यह मानते हुए कि कक्षा में अधिकतम 100 विद्यार्थी हैं और रोल नंबर 1 से 100 तक क्रमबद्ध हैं, हम जानते हैं कि RollNumber गुण के मानों को संग्रहित करने के लिए 3 अंक पर्याप्त हैं। इसलिए, इस गुण के लिए डेटा प्रकार INT उपयुक्त है। विद्यार्थियों के नामों (SName) में कुल वर्ण भिन्न हो सकते हैं। यह मानते हुए कि नाम में अधिकतम 20 वर्ण हैं, हम SName कॉलम के लिए VARCHAR(20) का उपयोग करते हैं। गुण SDateofBirth के लिए डेटा प्रकार DATE है और यह मानते हुए कि विद्यालय अभिभावक का 12 अंकों का आधार नंबर GUID के रूप में उपयोग करता है, हम GUID को CHAR(12) घोषित कर सकते हैं क्योंकि आधार नंबर निश्चित लंबाई का होता है और हम GUID पर कोई गणितीय संक्रिया नहीं करने वाले हैं।
तालिका 8.3, 8.4 और 8.5 क्रमशः संबंधों STUDENT, GUARDIAN और ATTENDANCE के प्रत्येक गुण के लिए चुने गए डेटा प्रकार और प्रतिबंध दिखाती हैं।
तालिका 8.3 संबंध STUDENT के गुणों के लिए डेटा प्रकार और प्रतिबंध
| Attribute Name | Data expected to be stored | Data type | Constraint |
|---|---|---|---|
| RollNumber | अधिकतम 3 अंकों की संख्यात्मक मान | INT | PRIMARY KEY |
| SName | अधिकतम 20 वर्णों की परिवर्तनीय लंबाई की स्ट्रिंग | VARCHAR(20) | NOT NULL |
| SDateofBirth | दिनांक मान | DATE | NOT NULL |
| GDID | 12 अंकों की संख्यात्मक मान | CHAR(12) | FOREIGN KEY |
तालिका 8.4 संबंध GUARDIAN के गुणों के लिए डेटा प्रकार और प्रतिबंध
| विशेषता नाम | संग्रहीत होने वाला डेटा | डेटा प्रकार | बाधा |
|---|---|---|---|
| GUID | 12 अंकों वाला आधार संख्या युक्त संख्यात्मक मान | CHAR (12) | PRIMARY KEY |
| GName | अधिकतम 20 वर्णों वाला परिवर्ती लंबाई स्ट्रिंग | VARCHAR (20) | NOT NULL |
| GPhone | 10 अंकों वाला संख्यात्मक मान | CHAR(10) | NULL UNIQUE |
| GAddress | 30 वर्णों के आकार वाला परिवर्ती लंबाई स्ट्रिंग | VARCHAR(30) | NOT NULL |
तालिका 8.5 संबंध ATTENDANCE की विशेषताओं के लिए डेटा प्रकार और बाधाएँ।
| विशेषता नाम | संग्रहीत होने वाला डेटा | डेटा प्रकार | बाधा |
|---|---|---|---|
| AttendanceDate | दिनांक मान | DATE | PRIMARY KEY* |
| RollNumber | अधिकतम 3 अंकों वाला संख्यात्मक मान | INT | PRIMARY KEY* FOREIGN KEY |
| AttendanceStatus | उपस्थित के लिए ‘P’ और अनुपस्थित के लिए ‘A’ | CHAR(1) | NOT NULL |
*का अर्थ है संयुक्त प्राथमिक कुंजी का भाग
एक बार डेटा प्रकार और बाधाओं की पहचान हो जाने के बाद, आइए सरलीकरण के लिए विशेषता नाम के साथ बाधा निर्दिष्ट किए बिना तालिकाएँ बनाते हैं। हम विशेषताओं पर बाधाओं को शामिल करना खंड 8.4.4 में सीखेंगे।
उदाहरण 8.1 तालिका STUDENT बनाना।
तालिका STUDENT बनाना।
mysql> CREATE TABLE STUDENT(
$\qquad$ -> RollNumber INT,
$\qquad$ -> SName VARCHAR(20),
$\qquad$ -> SDateofBirth DATE,
$\qquad$ -> GUID CHAR(12),
$\qquad$ -> PRIMARY KEY (RollNumber));
Query OK, 0 rows affected (0.91 sec)
नोट: ‘, दो विशेषताओं को अलग करने के लिए प्रयोग होता है और प्रत्येक कथन अर्धविराम (;) से समाप्त होता है। प्रतीक ‘->’ पंक्ति की निरंतरता को दर्शाता है क्योंकि SQL कथन एक ही पंक्ति में पूर्ण नहीं हो सकता।
सोचिए और विचार कीजिए
क्या हम संपर्क संख्या (मोबाइल, लैंडलाइन) के लिए CHAR या VARCHAR डेटा प्रकार रख सकते हैं?
8.4.3 DESCRIBE Table
हम पहले से बनाई गई तालिका की संरचना को describe कथन का उपयोग करके देख सकते हैं।
गतिविधि 8.4
अन्य दो संबंध GUARDIAN और ATTENDENCE को तालिका 8.4 और 8.5 में दिए गए डेटा प्रकारों के अनुसार बनाइए और उनकी संरचना देखिए। इन दोनों तालिकाओं में कोई भी बाधा न जोड़ें।
व्याकरण:
DESCRIBE tablename;
MySQL तालिका का विवरण प्राप्त करने के लिए DESCRI BE के संक्षिप्त रूप DESC को भी समर्थन करता है। STUDENT संबंध की संरचना के बारे में विवरण प्राप्त करने के लिए, हम तालिका नाम के बाद DESC या DESCRIBE लिख सकते हैं:
mysql>DESC STUDENT;
| Fleld | Tyoe | $\mathrm{Null}$ | Key | Default | Extra |
|---|---|---|---|---|---|
| Rol I Number | int | NO | PRI | NULL | |
| SName | varchar(20) | YES | NULL | ||
| SDateofBirth | date | YES | NULL | ||
| GUID | char(12) | YES | NULL |
4 rows in set (0.06 sec)
show table कमांड अब STUDENT तालिका को लौटाएगा:
mysqI > SHOW TABLES;
| Tables_in_studentattendence |
|---|
| student |
1 row in set (0.00 sec)
8.4.4 ALTER Table
टेबल बनाने के बाद हमें यह अहसास हो सकता है कि हमें कोई attribute जोड़ना या हटाना है, या किसी मौजूदा attribute का datatype बदलना है, या attribute में constraint जोड़ना है। ऐसे सभी मामलों में हमें alter statement का उपयोग करके टेबल की संरचना को बदलना या संशोधित करना होता है।
Syntax:
ALTER TABLE tablename ADD/Modify/DROP attribute1, attribute2,..
(A) किसी relation में primary key जोड़ना
आइए अब Activity 8.4 में बनाए गए टेबल्स को बदलें। नीचे दिया गया MySQL statement GUARDIAN relation में primary key जोड़ता है:
mysql> ALTER TABLE GUARDIAN ADD PRIMARY KEY (GUID);
Query OK, 0 rows affected (1.14 sec)
Records: 0 Duplicates: 0 Warnings: 0
अब आइए ATTENDANCE relation में primary key जोड़ें। इस relation की primary key एक composite key है जो दो attributes—AttendanceDate और RollNumber—से मिलकर बनी है।
mysql> ALTER TABLE ATTENDANCE
$\qquad$ -> ADD PRIMARY KEY(AttendanceDate,
$\qquad$ -> RollNumber);
Query OK, 0 rows affected (0.52 sec)
Records: 0 Duplicates: 0 Warnings: 0
(B) किसी relation में foreign key जोड़ना
एक बार primary keys जुड़ जाने के बाद अगला कदम relation में foreign keys जोड़ना है (यदि कोई हों)। किसी relation में multiple foreign keys हो सकते हैं और प्रत्येक foreign key एक single attribute पर परिभाषित होता है। Relation में foreign key जोड़ते समय निम्नलिखित बातों का ध्यान रखना चाहिए:
- संदर्भित संबंध पहले से ही बनाया जा चुका होना चाहिए।
- संदर्भित गुण संदर्भित संबंध की प्राथमिक कुंजी का हिस्सा होना चाहिए।
- संदर्भित और संदर्भित करने वाले गुणों के डेटा प्रकार और आकार समान होने चाहिए।
वाक्य रचना:
ALTER TABLE table name ADD FOREIGN KEY(attribute name) REFERENCES referenced_table_name (attribute name);
आइए अब STUDENT तालिका में विदेशी कुंजी जोड़ें। तालिका 8.3 दिखाती है कि गुण GUID (संदर्भित करने वाला गुण) एक विदेशी कुंजी है और यह तालिका GUARDIAN (तालिका 8.4) के गुण GUID (संदर्भित गुण) को संदर्भित करता है। इसलिए, STUDENT संदर्भित करने वाली तालिका है और GUARDIAN संदर्भित तालिका है।
mysql> ALTER TABLE STUDENT
$\qquad$ -> ADD FOREIGN KEY(GUID) REFERENCES
$\qquad$ -> GUARDIAN(GUID);
Query OK, 0 rows affected (0.75 sec)
Records: 0 Duplicates: 0 Warnings: 0
(C) मौजूदा गुण में UNIQUE बाधा जोड़ना
GUARDIAN तालिका में, गुण GPhone पर UNIQUE बाधा है जिसका अर्थ है उस स्तंभ में कोई भी दो मान समान नहीं होने चाहिए।
वाक्य रचना:
ALTER TABLE table name ADD UNIQUE (attribute name);
आइए अब GUARDIAN तालिका के गुण GPhone के साथ UNIQUE बाधा जोड़ें जैसा कि तालिका 8.4 में दिखाया गया है।
mysql> ALTER TABLE GUARDIAN
$\qquad$ -> ADD UNIQUE(GPhone);
Query OK, 0 rows affected (0.44 sec)
Records: 0 Duplicates: 0 Warnings: 0
गतिविधि 8.5
ATTENDANCE तालिका में विदेशी कुंजी जोड़ें (संदर्भित करने वाली और संदर्भित तालिकाओं की पहचान करने के लिए चित्र 8.1 का उपयोग करें)।
(D) किसी मौजूदा तालिका में एक विशेषता जोड़ना
कभी-कभी हमें किसी तालिका में एक अतिरिक्त विशेषता जोड़ने की आवश्यकता हो सकती है। इसे नीचे दी गई वाक्य-रचना का उपयोग करके किया जा सकता है:
ALTER TABLE table_name ADD attribute_name DATATYPE;
मान लीजिए स्कूल के प्रधानाचार्य ने कुछ जरूरतमंद छात्रों को छात्रवृत्ति देने का निर्णय लिया है, जिसके लिए अभिभावक की आय जानना आवश्यक है। लेकिन स्कूल ने अब तक तालिका GUARDIAN में आय विशेषता नहीं रखी है। इसलिए, डेटाबेस डिज़ाइनर को अब तालिका GUARDIAN में INT डेटा प्रकार की एक नई विशेषता income जोड़ने की आवश्यकता है।
mysql> ALTER TABLE GUARDIAN
$\qquad$ -> ADD income INT;
Query OK, 0 rows affected (0.47 sec)
Records: 0 Duplicates: 0 Warnings: 0
(E) किसी विशेषता का डेटा प्रकार संशोधित करना
हम निम्न ALTER कथन का उपयोग करके किसी तालिका की मौजूदा विशेषताओं के डेटा प्रकारों को संशोधित कर सकते हैं।
वाक्य-रचना:
ALTER TABLE table_name MODIFY attribute DATATYPE;
मान लीजिए हमें GUARDIAN तालिका की विशेषता GAddress का आकार $\operatorname{VARCHAR}(30)$ से $\operatorname{VARCHAR}(40)$ करना है। MySQL कथन होगा:
mysql> ALTER TABLE GUARDIAN
$\qquad$ -> MODIFY GAddress VARCHAR(40);
Query OK, 0 rows affected (0.11 sec)
Records: 0 Duplicates: 0 Warnings: 0
सोचिए और विचार कीजिए
आय विशेषता में न्यूनतम और अधिकतम आय मान क्या-क्या दर्ज किए जा सकते हैं, यदि डेटा प्रकार INT है?
(F) किसी विशेषता की बाधा संशोधित करना
जब हम एक टेबल बनाते हैं, तो डिफ़ॉल्ट रूप से प्रत्येक ऐट्रिब्यूट NULL मान लेता है, सिवाय उस ऐट्रिब्यूट के जिसे प्राइमरी की के रूप में परिभाषित किया गया है। हम ALTER स्टेटमेंट का उपयोग करके किसी ऐट्रिब्यूट की कंस्ट्रेंट को NULL से NOT NULL में बदल सकते हैं।
सिंटैक्स:
ALTER TABLE table_name MODIFY attribute DATATYPE NOT NULL;
नोट: MODIFY का उपयोग करते समय हमें ऐट्रिब्यूट का डेटा टाइप NOT NULL कंस्ट्रेंट के साथ निर्दिष्ट करना होता है।
टेबल STUDENT (टेबल 8.3) के ऐट्रिब्यूट SName के साथ NOT NULL कंस्ट्रेंट जोड़ने के लिए, हम निम्नलिखित MySQL स्टेटमेंट लिखते हैं:
mysql> ALTER TABLE STUDENT
$\qquad$ -> MODIFY SName VARCHAR(20) NOT NULL;
Query OK, 0 rows affected (0.47 sec)
Records: 0 Duplicates: 0 Warnings: 0
(G) किसी ऐट्रिब्यूट में डिफ़ॉल्ट मान जोड़ना
यदि हम किसी ऐट्रिब्यूट के लिए डिफ़ॉल्ट मान निर्दिष्ट करना चाहते हैं, तो निम्नलिखित सिंटैक्स का उपयोग करें:
ALTER TABLE table_name MODIFY attribute DATATYPE
DEFAULT default _ vālue;
STUDENT के SDateofBirth का डिफ़ॉल्ट मान 15 मई 2000 सेट करने के लिए, हम निम्नलिखित स्टेटमेंट लिखते हैं:
mysql> ALTER TABLE STUDENT
$\qquad$ -> MODIFY SDateofBirth DATE DEFAULT
$\qquad$ -> 2000-05-15;
Query OK, 0 rows affected (0.08 sec)
Records: 0 Duplicates: 0 Warnings: 0
नोट: MODIFY का उपयोग करते समय हमें ऐट्रिब्यूट का डेटा टाइप DEFAULT के साथ निर्दिष्ट करना होता है।
(H) किसी ऐट्रिब्यूट को हटाना
ALTER का उपयोग करके हम टेबल से ऐट्रिब्यूट्स को हटा सकते हैं, जैसा कि नीचे दिए गए सिंटैक्स में दिखाया गया है:
ALTER TABLE table_name DROP attribute;
टेबल GUARDIAN से attribute income को हटाने के लिए (8.4), हम निम्नलिखित MySQL statement लिख सकते हैं:
mysql> ALTER TABLE GUARDIAN DROP income;
Query OK, 0 rows affected (0.42 sec)
Records: 0 Duplicates: 0 Warnings: 0
(I) टेबल से primary key हटाना
जब हम कोई टेबल बनाते हैं, तो हमने गलत primary key specify किया हो सकता है। ऐसे में, हमें टेबल के मौजूदा primary key को drop करना होगा और एक नया primary key add करना होगा।
Syntax:
ALtER TABLE table_name DROP PRIMARY KEY;
टेबल GUARDIAN का primary key हटाने के लिए (Table 8.4), हम निम्नलिखित MySQL statement लिखते हैं:
mysql> ALTER TABLE GUARDIAN DROP PRIMARY KEY;
Query OK, 0 rows affected (0.72 sec)
Records: 0 Duplicates: 0 Warnings: 0
**
2) DROP statement आपके द्वारा बनाई गई तालिकाओं या डेटाबेस को हटा देगा। इसलिए आप अध्याय के अंत में DROP statement लगा सकते हैं।
8.5 डेटा मैनिपुलेशन के लिए SQL
पिछले खंड में, हमने तीन संबंधों STUDENT, GUARDIAN और ATTENDANCE वाला StudentAttendance डेटाबेस बनाया। जब हम कोई तालिका बनाते हैं, तो केवल इसकी संरचना बनती है लेकिन तालिका में कोई डेटा नहीं होता है। तालिका में रिकॉर्ड भरने के लिए, INSERT statement का उपयोग किया जाता है। इसी प्रकार, तालिका रिकॉर्ड्स को SQL डेटा मैनिपुलेशन statements का उपयोग करके हटाया या अपडेट किया जा सकता है।
डेटाबेस का उपयोग करके डेटा मैनिपुलेशन का अर्थ है या तो मौजूदा डेटा की पुनर्प्राप्ति (पहुंच), नए डेटा का सम्मिलन, मौजूदा डेटा की हटाना या डेटाबेस में मौजूदा डेटा में संशोधन।
8.5.1 रिकॉर्ड्स का सम्मिलन
INSERT INTO statement किसी तालिका में नए रिकॉर्ड्स सम्मिलित करने के लिए उपयोग की जाती है। इसका सिंटैक्स है:
INSERT INTO tablename
VALUES(value 1, value 2,….);
यहां, value 1 attribute 1 के अनुरूप है, value 2 attribute 2 के अनुरूप है और इसी तरह आगे। ध्यान दें कि हमें INSERT statement में attribute नाम निर्दिष्ट करने की आवश्यकता नहीं है यदि INSERT statement में मानों की संख्या तालिका में कुल attributes की संख्या के ठीक बराबर है।
सावधानी: जब किसी तालिका में विदेशी कुंजी के साथ रिकॉर्ड्स भरते हैं, तो सुनिश्चित करें कि संदर्भित तालिकाओं में रिकॉर्ड्स पहले से ही भरे गए हैं।
आइए स्टूडेंट अटेंडेंस डेटाबेस में कुछ रिकॉर्ड्स डालें। हम पहले GUARDIAN टेबल में रिकॉर्ड्स डालेंगे क्योंकि इसमें कोई फॉरेन की नहीं है। हम टेबल 8.6 में दिए गए रिकॉर्ड्स डालने जा रहे हैं।
टेबल 8.6 GUARDIAN टेबल में डाले जाने वाले रिकॉर्ड्स
| GUID | GName | GPhone | GAddress |
|---|---|---|---|
| 444444444444 | अमित अहूजा | 5711492685 | G-35, अशोक विहार, दिल्ली |
| 111111111111 | बाइचुंग भूटिया | 7110047139 | फ्लैट नं. 5, दार्जिलिंग अपार्टमेंट, शिमला |
| 101010101010 | हिमांशु शाह | 9818184855 | 26/77, वेस्ट पटेल नगर, अहमदाबाद |
| 333333333333 | डैनी डिसूजा | S-13, अशोक विलेज, दमन | |
| 466444444666 | सुजाता पी. | 7802983674 | HNO-13, B-ब्लॉक, प्रीत विहार, मदुरै |
नीचे दिया गया स्टेटमेंट टेबल में पहला रिकॉर्ड डालता है।
mysql> INSERT INTO GUARDIAN
$\qquad$ -> VALUES (444444444444, ‘अमित अहूजा’,
$\qquad$ -> 5711492685, ‘G-35, अशोक विहार, दिल्ली’);
Query OK, 1 row affected (0.01 sec)
हम डाले गए रिकॉर्ड्स देखने के लिए SQL स्टेटमेंट SELECT * from table name का उपयोग कर सकते हैं। SELECT स्टेटमेंट को अगले सेक्शन में समझाया जाएगा।
mysql> SELECT * from GUARDIAN;
| GUID | GName | Gphone | GAddress |
|---|---|---|---|
| 444444444444 | अमित अहूजा | 5711492685 | G-35, अशोक विहार, दिल्ली |
1 row in set (0.00 sec)
यदि हम किसी तालिका में केवल कुछ गुणों के लिए मान देना चाहते हैं (यह मानते हुए कि अन्य गुणों में NULL या कोई अन्य डिफ़ॉल्ट मान है), तो हम प्रत्येक डेटा मान के साथ गुण का नाम निर्दिष्ट करेंगे जैसा कि निम्नलिखित INSERT INTO कथन के सिंटैक्स में दिखाया गया है।
सिंटैक्स:
INSERT INTO tablename (column1, column2, …)
VALUES (value1, value2, …);
तालिका 8.6 के चौथे रिकॉर्ड को डालने के लिए जहाँ GPhone नहीं दिया गया है, हमें अन्य तीन फ़ील्डों में मान डालने की आवश्यकता है (GPhone को डिफ़ॉल्ट रूप से NULL सेट किया गया था जब तालिका बनाई गई थी)। इस स्थिति में, हमें उन गुणों के नाम निर्दिष्ट करने होंगे जिनमें हम मान डालना चाहते हैं। मान उसी क्रम में देने चाहिए जिस क्रम में गुण INSERT कमांड में लिखे गए हैं।
गतिविधि 8.6
तालिका 8.6 की शेष 3 पंक्तियों को तालिका GUARDIAN में डालने के लिए SQL कथन लिखें।
mysql> INSERT INTO GUARDIAN(GUID, GName, GAddress)
$\qquad$ -> VALUES (333333333333, ‘Danny Dsouza’,
$\qquad$ -> ‘S -13, Ashok Village, Daman’ );
Query OK, 1 row affected (0.03 sec)
नोट: टेक्स्ट और तिथि मानों को “’ (सिंगल कोट्स) में बंद करना चाहिए।
mysql>SELECT * from GUARDIAN;
| GUID | GName | Gphone | GAddress |
|---|---|---|---|
| 333333333333 | Danny Dsouza | NULL | S-13, Ashok Village, Daman |
| 444444444444 | Ami t Ahuja | 5711492685 | G.35, Ashok vihar, Delhi |
2 rows in set (0.00 sec)
अब हम तालिका 8.7 में दिए गए रिकॉर्डों को STUDENT तालिका में डालते हैं।
तालिका 8.7 STUDENT तालिका में डाले जाने वाले रिकॉर्ड
| RollNumber | SName | SDateofBirth | GUID |
|---|---|---|---|
| 1 | अथर्व आहूजा | 2003-05-15 | 444444444444 |
| 2 | डेज़ी भूटिया | 2002-02-28 | 11111111111 |
| 3 | तालीम शाह | 2002-02-28 | |
| 4 | जॉन डिसूज़ा | 2003-08-18 | 33333333333 |
| 5 | अली शाह | 2003-07-05 | 101010101010 |
तालिका 8.7 का पहला रिकॉर्ड डालने के लिए हम निम्नलिखित MySQL कथन लिखते हैं
mysql> INSERT INTO STUDENT
$\qquad$ -> VALUES(1,‘अथर्व आहूजा’,‘2003-05-15’,
$\qquad$ -> 444444444444);
Query OK, 1 row affected (0.11 sec)
या
mysql> INSERT INTO STUDENT (RollNumber, SName,
$\qquad$ -> SDateofBirth, GUID)
$\qquad$ -> VALUES (1,‘अथर्व आहूजा’,‘2003-05-15’,
$\qquad$ -> 444444444444);
Query OK, 1 row affected (0.02 sec)
mysql> SELECT * from STUDENT;
| RollNumber | SName | SDateofBirth | GUID |
|---|---|---|---|
| 1 | अथर्व आहूजा | 2003-05-15 | 444444444444 |
1 row in set (0.00 sec)
अब हम तालिका 8.7 का तीसरा रिकॉर्ड डालते हैं जिसमें GUID NULL है। याद रखें कि GUID इस तालिका की विदेशी कुंजी है और इसलिए NULL मान ले सकती है। इसलिए हम GUID के लिए NULL मान रख सकते हैं और निम्नलिखित कथन का उपयोग करके रिकॉर्ड डाल सकते हैं:
याद रखें कि दिनांक “YYYY-MM-DD” प्रारूप में संग्रहीत होता है।
mysql> INSERT INTO STUDENT
$\qquad$ -> VALUES(3, ‘तालीम शाह’,‘2002-02-28’,
$\qquad$ -> NULL);
Query OK, 1 row affected (0.05 sec)
mysq q >SELECT * from STUDENT;
| RollNumber | SName | SDateofBirth | GUID |
|---|---|---|---|
| 1 | अथर्व अहूजा | 2003-05-15 | 444444444444 |
| 3 | तालीम शाह | 2002-02-28 | NULL |
2 rows in set (0.00 sec)
हमें उपरोक्त MySQL कथन में NULL लिखना पड़ा क्योंकि जब कॉलम नाम नहीं देते, तो हमें सभी कॉलमों के लिए मान देने होते हैं। अन्यथा, यदि हमें केवल कुछ विशेष गुणों के लिए डेटा डालना है, तो हमें मानों के साथ-साथ गुणों के नाम भी देने होते हैं, जैसा कि अगले क्वेरी में दिखाया गया है:
गतिविधि 8.7
SQL कथन लिखिए ताकि तालिका 8.7 की शेष 4 पंक्तियों को STUDENT तालिका में डाला जा सके।
mysql> INSERT INTO STUDENT (RollNumber, SName,
$\qquad$ -> SDateofBirth) VALUES (3, ‘तालीम शाह’,’
$\qquad$ -> 2002-02-28’);
Query OK, 1 row affected (0.05 sec)
उपरोक्त कथन में हम DBMS को सूचित कर रहे हैं कि उल्लेखित कॉलमों के लिए संगत मान डाले जाएँ और GUID को NULL मान दिया जाएगा।
mysql> SELECT * from STUDENT;
| RollNumber | SName | SDateofBirth | GUID |
|---|---|---|---|
| 1 | अथर्व अहूजा | 2003-05-15 | 444444444444 |
| 3 | तालीम शाह | 2002-02-28 | NULL |
2 rows in set (0.00 sec)
सोचिए और विचार कीजिए
- उपरोक्त में से कौन-सा सिंटेक्स प्रयोग किया जाना चाहिए जब हमें यह सुनिश्चित नहीं हो कि मानों को तालिका में किस कॉलम के क्रम में डालना है?
- क्या हम एक ही रोल नंबर वाली दो रिकॉर्ड डाल सकते हैं?
8.6 डेटा क्वेरी के लिए SQL
अब तक हमने सीखा है कि डेटाबेस कैसे बनाया जाता है और डेटा को कैसे संग्रहित और हेरफेर किया जाता है। हम डेटा को डेटाबेस में संग्रहित करने में रुचि रखते हैं क्योंकि भविष्य में डेटाबेस से डेटा को जिस भी तरह चाहें पुनः प्राप्त करना आसान होता है। स्ट्रक्चर्ड क्वेरी लैंग्वेज (SQL) में MySQL डेटाबेस (या किसी अन्य RDBMS) में कई तालिकाओं में संग्रहित डेटा को पुनः प्राप्त करने के लिए कुशल तंत्र होते हैं। उपयोगकर्ता SQL कमांड दर्ज करता है जिन्हें क्वेरीज़ कहा जाता है जहाँ डेटा को पुनः प्राप्त करने के लिए विशिष्ट आवश्यकताएँ दी जाती हैं। SQL स्टेटमेंट SELECT डेटाबेस की तालिकाओं से डेटा पुनः प्राप्त करने के लिए प्रयोग किया जाता है और इसे क्वेरी स्टेटमेंट भी कहा जाता है।
8.6.1 SELECT Statement
SQL स्टेटमेंट SELECT डेटाबेस की तालिकाओं से डेटा पुनः प्राप्त करने के लिए प्रयोग किया जाता है और आउटपुट भी तालिका के रूप में प्रदर्शित किया जाता है।
Syntax:
SELECT attribute1, attribute2, …
FROM table_name
WHERE condition
यहाँ, attribute 1, attribute $2, \ldots$ तालिका table_name के कॉलम नाम हैं जिनसे हम डेटा पुनः प्राप्त करना चाहते हैं। FROM क्लॉज हमेशा SELECT क्लॉज के साथ लिखा जाता है क्योंकि यह उस तालिका का नाम निर्दिष्ट करता है जिससे डेटा पुनः प्राप्त किया जाना है। WHERE क्लॉज वैकल्पिक है और निर्दिष्ट शर्त(ओं) को पूरा करने वाले डेटा को पुनः प्राप्त करने के लिए प्रयोग किया जाता है।
Example 8.2 रोल नंबर 2 वाले छात्र का नाम और जन्म तिथि प्रदर्शित करने के लिए, हम निम्नलिखित क्वेरी लिखते हैं:
mysql> SELECT SName, SDateofBirth
$\qquad$ -> FROM STUDENT
$\qquad$ -> WHERE RollNumber = 1;
| SName | SDateofBirth |
|---|---|
| Atharv Ahuja | 2003-05-15 |
1 row in set (0.03 sec)
सोचिए और विचार कीजिए
क्या आप दैनिक जीवन के ऐसे उदाहरणों के बारे में सोच सकते हैं जहाँ डेटा को डेटाबेस में संग्रहित करना और उस पर क्वेरी करना उपयोगी हो सकता है?
8.6.2 डेटाबेस OFFICE का उपयोग करके क्वेरी करना
विभिन्न संगठन डेटा को तालिकाओं के रूप में संग्रहित करने के लिए डेटाबेस बनाए रखते हैं। आइए किसी संगठन के डेटाबेस OFFICE पर विचार करें जिसमें EMPLOYEE, DEPARTMENT आदि कई संबंधित तालिकाएँ हैं। डेटाबेस में हर EMPLOYEE किसी DEPARTMENT को सौंपा जाता है और उसका विभाग संख्या (DeptId) EMPLOYEE तालिका में विदेशी कुंजी के रूप में संग्रहित होता है। आइए तालिका ‘EMPLOYEE’ के लिए कुछ डेटा पर विचार करें जैसा कि तालिका 8.8 में दिखाया गया है और डेटा पुनः प्राप्त करने के लिए SELECT कथन लागू करें:
तालिका 8.8 EMPLOYEE
| EmpNo | Ename | Salary | Bonus | Deptld |
|---|---|---|---|---|
| 101 | आलिया | 10000 | 234 | D02 |
| 102 | कृतिका | 60000 | 123 | D01 |
| 103 | शब्बीर | 45000 | 566 | D01 |
| 104 | गुरप्रीत | 19000 | 565 | D04 |
| 105 | जोसेफ़ | 34000 | 875 | D03 |
| 106 | सान्या | 48000 | 695 | D02 |
| 107 | वर्गीस | 15000 | D01 | |
| 108 | नाचाओबी | 29000 | D05 | |
| 109 | दारिभा | 42000 | D04 | |
| 110 | तान्या | 50000 | 467 | D05 |
(A) चयनित कॉलम पुनः प्राप्त करना
निम्नलिखित क्वेरी सभी कर्मचारियों के कर्मचारी संख्याओं को प्रदर्शित करती है:
mysql> SELECT EmpNo
$\qquad$ -> FROM EMPLOYEE;
| EmpNo |
|---|
| 101 |
| 102 |
| 103 |
| 104 |
| 105 |
| 106 |
| 107 |
| 108 |
| 109 |
| 110 |
10 rows in set (0.41 sec)
सभी कर्मचारियों का कर्मचारी संख्या और कर्मचारी नाम प्रदर्शित करने के लिए, हम निम्नलिखित क्वेरी लिखते हैं:
mysql> SELECT EmpNo, Ename
$\qquad$ -> FROM EMPLOYEE;
| EmpNo | Ename |
|---|---|
| 101 | आलिया |
| 102 | कृतिका |
| 103 | शब्बीर |
| 104 | गुरप्रीत |
| 105 | जोसेफ |
| 106 | सान्या |
| 107 | वर्गीस |
| 108 | नाचाओबी |
| 109 | दारिभा |
| 110 | तान्या |
10 rows in set (0.00 sec)
(B) कॉलम का नाम बदलना
यदि हम आउटपुट प्रदर्शित करते समय किसी कॉलम का नाम बदलना चाहें, तो हम क्वेरी में उपनाम ‘AS’ का उपयोग कर ऐसा कर सकते हैं:
सभी कर्मचारियों के लिए आउटपुट में कर्मचारी नाम को नाम के रूप में प्रदर्शित करें।
mysql> SELECT EName AS Name
$\qquad$-> FROM EMPLOYEE;
| Name |
|---|
| आलिया |
| कृतिका |
| शब्बीर |
| गुरप्रीत |
| जोसेफ |
| सान्या |
| वर्गीस |
| नाचाओबी |
| दारिभा |
| तान्या |
10 rows in set (0.00 sec)
उदाहरण 8.3 सभी कर्मचारियों के नाम उनके वार्षिक वेतन (वेतन*12) के साथ प्रदर्शित करें। क्वेरी परिणाम प्रदर्शित करते समय EName को नाम के रूप में नाम बदलें।
mysql> SELECT EName AS Name, Salary*12
$\qquad$ -> FROM EMPLOYEE;
| Name | Salary*12 |
|---|---|
| आलिया | 120000 |
| कृतिका | 720000 |
| शब्बीर | 540000 |
| गुरप्रीत | 228000 |
| जोसेफ | 408000 |
| सान्या | 576000 |
| वर्गीस | 180000 |
| नाचाओबी | 348000 |
| दारिभा | 504000 |
| तान्या | 600000 |
10 rows in set (0.02 sec)
ध्यान दें कि आउटपुट में, Salary*12 को वार्षिक वेतन कॉलम के लिए कॉलम नाम के रूप में प्रदर्शित किया गया है। आउटपुट टेबल में हम उस कॉलम को Annual Salary के रूप में रीनेम करने के लिए उपनाम (alias) का उपयोग कर सकते हैं जैसा कि नीचे दिखाया गया है:
mysql> SELECT Ename AS Name, Salary*12 AS
$\qquad$ -> ‘Annual Salary’
$\qquad$ -> FROM EMPLOYEE;
| Name | Annual Salary |
|---|---|
| Aaliya | 120000 |
| Kritika | 720000 |
| Shabbir | 540000 |
| Gurpreet | 228000 |
| Joseph | 408000 |
| Sanya | 576000 |
| Vergese | 180000 |
| Nachaobi | 348000 |
| Daribha | 504000 |
| Tanya | 600000 |
10 rows in set (0.00 sec)
नोट:
i) Annual Salary को डेटाबेस टेबल में नए कॉलम के रूप में नहीं जोड़ा जाएगा। यह केवल क्वेरी के आउटपुट को प्रदर्शित करने के लिए है।
ii) यदि उपनाम वाला कॉलम नाम में स्पेस हो जैसे Annual Salary के मामले में, तो इसे उद्धरण चिह्नों में लिखना चाहिए जैसे ‘Annual Salary’.
(C) DISTINCT Clause
डिफ़ॉल्ट रूप से, SQL क्वेरी के माध्यम से प्राप्त सभी डेटा को आउटपुट के रूप में दिखाता है। हालांकि, डुप्लिकेट मान हो सकते हैं। जब SELECT स्टेटमेंट DISTINCT क्लॉज के साथ संयुक्त होता है, तो ये दोहराव के बिना रिकॉर्ड लौटाता है (अलग-अलग रिकॉर्ड)। उदाहरण के लिए, कर्मचारी के विभाग नंबर को पुनः प्राप्त करते समय डुप्लिकेट मान हो सकते हैं क्योंकि कई कर्मचारी एक ही विभाग को सौंपे गए होते हैं। सभी कर्मचारियों के लिए अद्वितीय विभाग नंबर प्रदर्शित करने के लिए हम DISTINCT का उपयोग करते हैं जैसा कि नीचे दिखाया गया है:
mysql> SELECT DISTINCT DeptId
$\qquad$ -> FROM EMPLOYEE;
| DeptId |
|---|
| D02 |
| D01 |
| D04 |
| D03 |
| D05 |
5 rows in set (0.03 sec)
(D) WHERE Clause
WHERE क्लॉज़ का उपयोग उन डेटा को पुनः प्राप्त करने के लिए किया जाता है जो कुछ निर्दिष्ट शर्तों को पूरा करते हैं। OFFICE डेटाबेस में, एक से अधिक कर्मचारियों की समान वेतन हो सकती है। विभाग संख्या D01 में कार्यरत कर्मचारियों के विशिष्ट वेतन को प्रदर्शित करने के लिए, हम निम्नलिखित क्वेरी लिखते हैं जिसमें उस कर्मचारी को चुनने की शर्त जिसका विभाग संख्या D01 है, WHERE क्लॉज़ का उपयोग करके निर्दिष्ट की गई है:
mysql> SELECT DISTINCT Salary
$\qquad$ -> FROM EMPLOYEE
$\qquad$ -> WHERE Deptid=‘D01’;
चूंकि कॉलम DeptId स्ट्रिंग प्रकार का है, इसके मान उद्धरण चिह्नों में लिखे जाते हैं (‘D01’)।
| Salary |
|---|
| 60000 |
| 45000 |
| 15000 |
3 rows in set (0.02 sec
उपरोक्त उदाहरण में, हमने WHERE क्लॉज़ में = ऑपरेटर का उपयोग किया है। हम अन्य संबंधात्मक ऑपरेटरों (<, <=, >, >=, !=) का भी उपयोग कर सकते हैं शर्तों को निर्दिष्ट करने के लिए। लॉजिकल ऑपरेटर AND, OR, और NOT का उपयोग WHERE क्लॉज़ के साथ कई शर्तों को जोड़ने के लिए किया जाता है।
उदाहरण 8.4 उन सभी कर्मचारियों को प्रदर्शित करें जो 5000 से अधिक कमाते हैं और DeptId D04 वाले विभाग में कार्यरत हैं।
mysql> SELECT *
$\qquad$ -> FROM EMPLOYEE
$\qquad$ -> WHERE Salary > 5000 AND DeptId = ‘D04’;
| EmpNo | Ename | Salary | Bonus | DeptId |
|---|---|---|---|---|
| 104 | Gurpreet | 19000 | 565 | D04 |
| 109 | Daribha | 42000 | NULL | D04 |
2 rows in set (0.00 sec)
उदाहरण 8.5 निम्नलिखित क्वेरी सभी कर्मचारियों के रिकॉर्ड प्रदर्शित करती है सिवाय Aaliya के।
mysql> SELECT *
$\qquad$ -> FROM EMPLOYEE
$\qquad$ -> WHERE NOT Ename = ‘Aaliya’;
| EmpNo | Ename | Salary | Bonus | DeptId |
|---|---|---|---|---|
| 102 | कृतिका | 60000 | 123 | D01 |
| 103 | शब्बीर | 45000 | 566 | D01 |
| 104 | गुरप्रीत | 19000 | 565 | D04 |
| 105 | जोसेफ | 34000 | 875 | D03 |
| 106 | सान्या | 48000 | 695 | D02 |
| 107 | वर्गीस | 15000 | NULL | D01 |
| 108 | नचाओबी | 29000 | NULL | D05 |
| 109 | दारिभा | 42000 | NULL | D04 |
| 110 | तान्या | 50000 | 467 | D05 |
9 rows in set (0.00 sec)
सोचिए और विचार कीजिए
यदि उपरोक्त क्वेरी में हम “Aaliya” को “AALIYA” या “aaliya” या “AaLIYA” लिखें तो क्या होगा? क्या क्वेरी समान आउटपुट देगी या त्रुटि उत्पन्न करेगी?
उदाहरण 8.6 निम्नलिखित क्वेरी उन सभी कर्मचारियों के नाम और विभाग संख्या प्रदर्शित करती है जो 20000 और 50000 के बीच वेतन अर्जित कर रहे हैं (दोनों मान सम्मिलित हैं).
mysql> SELECT Ename, DeptId
$\qquad$ -> FROM EMPLOYEE
$\qquad$ -> WHERE Salary>=20000 AND Salary<=50000;
| Ename | DeptId |
|---|---|
| शब्बीर | D01 |
| जोसेफ | D03 |
| सान्या | D02 |
| नचाओबी | D05 |
| दारिभा | D04 |
| तान्या | D05 |
6 rows in set (0.00 sec)
गतिविधि 8.8
उदाहरण 8.6 में दी गई क्वेरी और निम्नलिखित क्वेरी द्वारा उत्पन्न आउटपुट की तुलना कीजिए और OR तथा AND ऑपरेटरों के बीच अंतर कीजिए।
SELECT *
FROM EMPLOYEE
WHERE Salary > 5000 OR
$\qquad$ Dept I =20;
उपरोक्त क्वेरी एक रेंज को परिभाषित करती है जिसे तुलना ऑपरेटर BETWEEN का उपयोग करके भी जाँचा जा सकता है।
mysql> SELECT Ename, DeptId
$\qquad$ -> FROM EMPLOYEE
$\qquad$ -> WHERE Salary BETWEEN 20000 AND 50000;
| Ename | DeptId |
|---|---|
| Shabbir | D01 |
| Joseph | D03 |
| Sanya | D02 |
| Nachaobi | D05 |
| Daribha | D04 |
| Tanya | D05 |
6 rows in set (0.03 sec)
नोट: BETWEEN ऑपरेटर मानों की एक रेंज को परिभाषित करता है जिसमें कॉलम का मान आना चाहिए ताकि शर्त सत्य हो सके।
उदाहरण 8.7 निम्नलिखित क्वेरी उन सभी कर्मचारियों का विवरण प्रदर्शित करती है जो या तो DeptId D01, D02 या D04 में कार्यरत हैं।
mysql> SELECT *
$\qquad$ -> FROM EMPLOYEE
$\qquad$ -> WHERE DeptId = ‘D01’ OR DeptId = ‘D02’ OR
$\qquad$ -> DeptId = ‘D04’;
| EmpNo | Ename | Salary | Bonus | DeptId |
|---|---|---|---|---|
| 101 | Aaliya | 10000 | 234 | D02 |
| 102 | Kritika | 60000 | 123 | D01 |
| 103 | Shabbir | 45000 | 566 | D01 |
| 104 | Gurpreet | 19000 | 565 | D04 |
| 106 | Sanya | 48000 | 695 | D02 |
| 107 | Vergese | 15000 | NULL | D01 |
| 109 | Daribha | 42000 | NULL | D04 |
7 rows in set (0.00 sec)
(E) सदस्यता ऑपरेटर IN
IN ऑपरेटर एक मान की तुलना मानों के समूह से करता है और सत्य लौटाता है यदि वह मान उस समूह से संबंधित हो। उपरोक्त क्वेरी को I $\mathrm{N}$ ऑपरेटर का उपयोग करके नीचे दिखाए अनुसार पुनः लिखा जा सकता है:
mysql> SELECT*
-> FROM EMPLOYEE
-> WHERE DeptId IN (‘D01’, ‘D02’ , ‘D04’);
| EmpNo | Ename | Salary | Bonus | DeptId |
|---|---|---|---|---|
| 101 | आलिया | 10000 | 234 | D02 |
| 102 | कृतिका | 60000 | 123 | D01 |
| 103 | शब्बीर | 45000 | 566 | D01 |
| 104 | गुरप्रीत | 19000 | 565 | D04 |
| 106 | सान्या | 48000 | 695 | D02 |
| 107 | वर्गीज़ | 15000 | NULL | D01 |
| 109 | दारिभा | 42000 | NULL | D04 |
7 पंक्तियाँ सेट में (0.00 sec)
उदाहरण 8.8 निम्नलिखित क्वेरी उन सभी कर्मचारियों का विवरण प्रदर्शित करती है जो विभाग संख्या D01 या D02 में कार्यरत नहीं हैं।
mysql> SELECT *
$\qquad$ -> FROM EMPLOYEE
$\qquad$ -> WHERE DeptId NOT IN(‘D01’, ‘D02’);
| EmpNo | Ename | Salary | Bonus | DeptId |
|---|---|---|---|---|
| 104 | गुरप्रीत | 19000 | 565 | D04 |
| 105 | जोसेफ़ | 34000 | 875 | D03 |
| 108 | नाचाओबी | 29000 | NULL | D05 |
| 109 | दारिभा | 42000 | NULL | D04 |
| 110 | तान्या | 50000 | 467 | D05 |
5 पंक्तियाँ सेट में (0.00 sec)
नोट: यहाँ हमें NOT को IN के साथ संयोजित करना होता है क्योंकि हमें DeptId D01 और D02 को छोड़कर सभी रिकॉर्ड प्राप्त करने हैं।
(F) ORDER BY क्लॉज़
ORDER BY क्लॉज़ डेटा को किसी निर्दिष्ट कॉलम के संबंध में क्रमबद्ध (व्यवस्थित) रूप में प्रदर्शित करने के लिए प्रयोग की जाती है। डिफ़ॉल्ट रूप से, ORDER BY निर्दिष्ट कॉलम के मानों के आरोही क्रम में रिकॉर्ड प्रदर्शित करता है। रिकॉर्डों को अवरोही क्रम में प्रदर्शित करने के लिए उस कॉलम के साथ DES (अर्थात् descending) कीवर्ड लिखना आवश्यक होता है।
उदाहरण 8.9 निम्नलिखित क्वेरी सभी कर्मचारियों का विवरण उनके वेतन के आरोही क्रम में प्रदर्शित करती है।
mysql> SELECT *
$\qquad$ -> FROM EMPLOYEE
$\qquad$ -> ORDER BY Salary;
| EmpNo | Ename | Salary | Bonus | DeptId |
|---|---|---|---|---|
| 101 | आलिया | 10000 | 234 | D02 |
| 107 | वर्गीज़ | 15000 | NULL | D01 |
| 104 | गुरप्रीत | 19000 | 565 | D04 |
| 108 | नचाओबी | 29000 | NULL | D05 |
| 105 | जोसेफ | 34000 | 875 | D03 |
| 109 | दारिभा | 42000 | NULL | D04 |
| 103 | शब्बीर | 45000 | 566 | D01 |
| 106 | सान्या | 48000 | 695 | D02 |
| 110 | तान्या | 50000 | 467 | D05 |
| 102 | कृतिका | 60000 | 123 | D01 |
10 rows in set (0.05 sec)
उदाहरण 8.10 निम्नलिखित क्वेरी सभी कर्मचारियों का विवरण उनके वेतन के अनुसार अवरोही क्रम में प्रदर्शित करती है।
mysql> SELECT *
$\qquad$ -> FROM EMPLOYEE
$\qquad$ -> ORDER BY Salary DESC;
| EmpNo | Ename | Salary | Bonus | DeptId |
|---|---|---|---|---|
| 102 | कृतिका | 60000 | 123 | D01 |
| 110 | तान्या | 50000 | 467 | D05 |
| 106 | सान्या | 48000 | 695 | D02 |
| 103 | शब्बीर | 45000 | 566 | D01 |
| 109 | दारिभा | 42000 | NULL | D04 |
| 105 | जोसेफ | 34000 | 875 | D03 |
| 108 | नचाओबी | 29000 | NULL | D05 |
| 104 | गुरप्रीत | 19000 | 565 | D04 |
| 107 | वर्गीज़ | 15000 | NULL | D01 |
| 101 | आलिया | 10000 | 234 | D02 |
10 rows in set (0.00 sec)
(G) NULL मानों को संभालना
SQL एक विशेष मान NULL का समर्थन करता है जो एक गुम या अज्ञात मान को दर्शाने के लिए प्रयोग किया जाता है। उदाहरण के लिए, address नामक तालिका में village स्तंभ का मान शहरों के लिए नहीं होगा। इसलिए, ऐसे अज्ञात मानों को दर्शाने के लिए NULL का प्रयोग किया जाता है। यह ध्यान देना महत्वपूर्ण है क NULL 0 (शून्य) से भिन्न होता है। साथ ही, NULL मान के साथ कोई भी अंकगणितीय संक्रिया NULL देती है। उदाहरण: $5+$ NULL $=$ NULL क्योंकि NULL अज्ञात है इसलिए परिणाम भी अज्ञात है। किसी स्तंभ में NULL मान की जांच करने के लिए हम IS NULL का प्रयोग करते हैं।
गतिविधि 8.9
निम्नलिखित दो क्वेरीज़ को चलाइए और पता लगाइए कि यदि हम ORDER BY खंड में दो स्तंभ निर्दिष्ट करें तो क्या होगा:
SELECT *
FROM EMPLOYEE
ORDER BY Salary,Bonus
desc;
उदाहरण 8.11 निम्नलिखित क्वेरी उन सभी कर्मचारियों का विवरण प्रदर्शित करती है जिन्हें बोनस नहीं दिया गया है। इसका तात्पर्य है कि bonus स्तंभ खाली होगा।
mysql> SELECT *
$\qquad$ -> FROM EMPLOYEE
$\qquad$ -> WHERE Bonus IS NULL;
| EmpNo | Ename | Salary | Bonus | DeptId |
|---|---|---|---|---|
| 107 | Vergese | 15000 | NULL | D01 |
| 108 | Nachaobi | 29000 | NULL | D05 |
| 109 | Daribha | 42000 | NULL | D04 |
3 rows in set (0.00 sec)
उदाहरण 8.12 निम्नलिखित क्वेरी उन सभी कर्मचारियों के नाम प्रदर्शित करती है जिन्हें बोनस दिया गया है। इसका तात्पर्य है कि bonus स्तंभ खाली नहीं होगा।
mysql> SELECT EName
$\qquad$ -> FROM EMPLOYEE
$\qquad$ -> WHERE Bonus IS NOT NULL;
| EName |
|---|
| आलिया |
| कृतिका |
| शब्बीर |
| गुरप्रीत |
| जोसेफ |
| सान्या |
| तान्या |
7 rows in set (0.00 sec)
(H) सबस्ट्रिंग पैटर्न मिलान
कई बार हम ऐसी स्थितियों का सामना करते हैं जहाँ हम सटीक टेक्स्ट या मान से मिलान करके क्वेरी नहीं करना चाहते। बल्कि, हम केवल कुछ वर्णों या मानों का कॉलम मानों में मिलान खोजने में रुचि रखते हैं। उदाहरण के लिए, उन नामों को खोजना जो ‘T’ से शुरू होते हैं या उन पिन कोड्स को खोजना जो ‘60’ से शुरू होते हैं। इसे सबस्ट्रिंग पैटर्न मिलान कहा जाता है। हम ऐसे पैटर्न को = ऑपरेटर का उपयोग करके नहीं मिला सकते क्योंकि हम सटीक मिलान नहीं खोज रहे हैं। SQL LIKE ऑपरेटर प्रदान करता है जिसे WHERE क्लॉज़ के साथ उपयोग किया जा सकता है ताकि किसी कॉलम में निर्दिष्ट पैटर्न की खोज की जा सके।
LIKE ऑपरेटर निम्नलिखित दो वाइल्डकार्ड वर्णों का उपयोग करता है:
- % (प्रतिशत) — शून्य, एक या अनेक वर्णों को दर्शाने के लिए उपयोग किया जाता है
- _ (अंडरस्कोर) — एकल वर्ण को दर्शाने के लिए उपयोग किया जाता है
उदाहरण 8.13 निम्नलिखित क्वेरी उन सभी कर्मचारियों का विवरण प्रदर्शित करती है जिनके नाम ‘K’ से शुरू होते हैं।
mysql> SELECT *
$\qquad$ -> FROM EMPLOYEE
$\qquad$ -> WHERE Ename LIKE ‘K%’;
| EmpNo | Ename | Salary | Bonus | DeptId |
|---|---|---|---|---|
| 102 | Kritika | 60000 | 123 | D01 |
1 row in set (0.00 sec)
उदाहरण 8.14 निम्नलिखित क्वेरी उन सभी कर्मचारियों का विवरण प्रदर्शित करती है जिनके नाम ‘a’ पर समाप्त होते हैं।
mysql> SELECT *
$\qquad$ -> FROM EMPLOYEE
$\qquad$ -> WHERE Ename LIKE ‘%a’;
| EmpNo | Ename | Salary | Bonus | DeptId |
|---|---|---|---|---|
| 101 | आलिया | 10000 | 234 | D02 |
| 102 | कृतिका | 60000 | 123 | D01 |
| 106 | सान्या | 48000 | 695 | D02 |
| 109 | दारिभा | 42000 | NULL | D04 |
| 110 | तान्या | 50000 | 467 | D05 |
5 rows in set (0.00 sec)
उदाहरण 8.15 निम्नलिखित क्वेरी उन सभी कर्मचारियों का विवरण प्रदर्शित करती है जिनके नाम में ठीक 5 अक्षर होते हैं और कोई भी अक्षर से शुरू होते हैं लेकिन उसके बाद ‘ANYA’ होता है।
mysql> SELECT *
$\qquad$ -> FROM EMPLOYEE
$\qquad$ _-> WHERE Ename LIKE ‘ANYA’;
| EmpNo | Ename | Salary | Bonus | DeptId |
|---|---|---|---|---|
| 106 | Sanya | 48000 | 695 | D02 |
| 110 | Tanya | 50000 | 467 | D05 |
2 rows in set (0.00 sec)
सोचिए और विचार कीजिए
जब हम अपने मोबाइल फोन में संपर्क सूची में किसी संपर्क के नाम का पहला अक्षर टाइप करते हैं, तो उस अक्षर वाले सभी नाम प्रदर्शित होते हैं। क्या आप SQL स्टेटमेंट को इस प्रक्रिया से संबंधित कर सकते हैं? अन्य वास्तविक जीवन की स्थितियों की सूची बनाइए जहाँ आप SQL स्टेटमेंट को कार्यरत देख सकते हैं। $\rightarrow$ FROM EMPLOYEE
उदाहरण 8.16 निम्नलिखित क्वेरी उन सभी कर्मचारियों के नाम प्रदर्शित करती है जिनके नाम में ‘se’ उपस्ट्रिंग के रूप में होता है।
mysql> SELECT Ename
$\qquad$ -> FROM EMPLOYEE
$\qquad$ -> WHERE Ename LIKE ‘%se%’;
| Ename |
|---|
| Joseph |
| Vergese |
2 rows in set (0.00 sec)
उदाहरण 8.17 निम्नलिखित क्वेरी उन सभी कर्मचारियों के नाम प्रदर्शित करती है जिनके नाम में दूसरे स्थान पर ‘a’ होता है।
mysql> SELECT EName
$\qquad$ -> FROM EMPLOYEE
$\qquad$ _-> WHERE Ename LIKE ‘a%’;
| EName |
|---|
| आलिया |
| सान्या |
| नचाओबी |
| दारिभा |
| तान्या |
5 पंक्तियाँ सेट में (0.00 sec)
8.7 डेटा अद्यतन और विलोपन
डेटा का अद्यतन और विलोपन भी SQL डेटा हेरफेर के भाग हैं। इस खंड में हम इन दो डेटा हेरफेर विधियों को लागू करने जा रहे हैं।
8.7.1 डेटा अद्यतन
हमें किसी तालिका में मौजूदा रिकॉर्ड्स की एक या अधिक कॉलमों के मानों में बदलाव करने की आवश्यकता हो सकती है। उदाहरण के लिए, हमें पते, फोन नंबर या नाम की वर्तनी आदि में कुछ बदलाव की आवश्यकता हो सकती है। ऐसे संशोधन मौजूदा डेटा में करने के लिए UPDATE कथन का उपयोग किया जाता है।
वाक्य रचना:
UPDATE table_name
SET attribute1 = value1, attribute2 = value2, …
WHERE condition;
STUDENT तालिका 8.7 में रोल नंबर 3 के छात्र के लिए GUID का मान NULL है। साथ ही, मान लीजिए कि रोल नंबर 3 और 5 के छात्र भाई-बहन हैं। इसलिए, STUDENT तालिका में हमें रोल नंबर 3 के छात्र के लिए GUID मान 101010101010 भरना होगा। किसी विशेष पंक्ति (रिकॉर्ड) का GUID अद्यतन या बदलने के लिए हमें WHERE खंड का उपयोग करके उस रिकॉर्ड को निर्दिष्ट करना होगा, जैसा कि नीचे दिखाया गया है:
mysql> UPDATE STUDENT
$\qquad$ -> SET GUID = 101010101010
$\qquad$ -> WHERE RollNumber = 3;
Query OK, 1 पंक्ति प्रभावित (0.06 sec)
Rows matched: 1 Changed: 1 Warnings: 0
हम तब अद्यतन डेटा को SELECT * FROM STUDENT कथन का उपयोग करके सत्यापित कर सकते हैं।
चेतावनी: यदि हम UPDATE कथन में where क्लॉज़ छोड़ देते हैं तो सभी रिकॉर्ड्स का GUID 101010101010 में बदल जाएगा।
हम UPDATE कथन का उपयोग करके एक से अधिक कॉलम के मान भी अपडेट कर सकते हैं। मान लीजिए, GUID 466444444666 वाले अभिभावक (तालिका 8.6) ने पता ‘WZ - 68, Azad Avenue, Bijnour, MP’ और फ़ोन नंबर ‘9010810547’ बदलने का अनुरोध किया है।
mysql> UPDATE GUARDIAN
$\qquad$ -> SET GAddress = ‘WZ - 68, Azad Avenue,
$\qquad$ -> Bijnour, MP’, GPhone = 9010810547
$\qquad$ -> WHERE GUID = 466444444666;
Query OK, 1 row affected (0.06 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT * FROM GUARDIAN ;
| GUID | GName | Gphone | GAddress |
|---|---|---|---|
| 444444444444 | Amit Ahuja | 5711492685 | G-35, Ashok vihar, Delhi |
| 111111111111 | Baichung Bhutia | 7110047139 | Flat no. 5, Darjeeling Appt., Shimla |
| 101010101010 | Himanshu Shah | 9818184855 | 26/77, West Patel Nagar, Ahmedabad |
| 333333333333 | Danny Dsouza | NULL | S -13, Ashok Village, Daman |
| 466444444666 | Sujata P. | 9010810547 | WZ - 68, Azad Avenue, Bijnour, MP |
5 rows in set (0.00 sec)
8.7.2 डेटा विलोपन
DELETE कथन का उपयोग तालिका से एक या अधिक रिकॉर्ड(स) को हटाने के लिए किया जाता है।
वाक्य-रचना:
DELETE FROM table_name
WHERE condition;
मान लीजिए रोल नंबर 2 वाला छात्र स्कूल छोड़ चुका है। हम STUDENT तालिका से उस रिकॉर्ड को हटाने के लिए निम्नलिखित MySQL कथन का उपयोग कर सकते हैं।
mysql> DELETE FROM STUDENT WHERE RollNumber = 2;
Query OK, 1 row affected (0.06 sec)
mysql> SELECT * FROM STUDENT ;
| RollNumber | SName | SDateofBirth | GUID |
|---|---|---|---|
| 1 | Atharv Ahuja | 2003-05-15 | 444444444444 |
| 3 | Taleem Shah | 2002-02-28 | 101010101010 |
| 4 | John Dsouza | 2003-08-18 | 333333333333 |
| 5 | Ali Shah | 2003-07-05 | 101010101010 |
| 6 | Manika P. | 2002-03-10 | 466444444666 |
5 rows in set (0.00 sec)
सावधानी: UPDATE कथन की तरह, किसी तालिका में रिकॉर्ड हटाते समय DELETE कथन का उपयोग करते समय WHERE खंड शामिल करने के लिए हमें सावधान रहना होगा। अन्यथा, तालिका में सभी रिकॉर्ड हट जाएंगे।
सारांश
- डेटाबेस संबंधित तालिकाओं का एक संग्रह होता है। MySQL एक ‘संबंधपरक’ DBMS है। एक तालिका पंक्तियों और स्तंभों का संग्रह होता है, जहाँ प्रत्येक पंक्ति एक रिकॉर्ड होती है और स्तंभ रिकॉर्ड्स की विशेषता का वर्णन करते हैं।
- SQL अधिकांश RDBMS के लिए मानक भाषा है। SQL केस असंवेदनशील है।
- CREATE DATABASE कथन का उपयोग एक नए डेटाबेस को बनाने के लिए किया जाता है।
- USE कथन निर्दिष्ट डेटाबेस को सक्रिय डेटाबेस बनाने के लिए उपयोग किया जाता है।
- CREATE TABLE कथन का उपयोग एक तालिका बनाने के लिए किया जाता है।
- CREATE TABLE कथन में प्रत्येक गुण का एक नाम और डेटाटाइप होना चाहिए।
- ALTER TABLE कथन का उपयोग तालिका की संरचना में बदलाव करने के लिए किया जाता है जैसे स्तंभ(ओं) को जोड़ना, हटाना या डेटाटाइप बदलना।
- तालिका नाम के साथ DESC कथन तालिका की संरचना दिखाता है।
- INSERT INTO कथन का उपयोग तालिका में रिकॉर्ड(स) डालने के लिए किया जाता है।
- UPDATE कथन का उपयोग तालिका में मौजूदा डेटा को संशोधित करने के लिए किया जाता है।
- DELETE कथन का उपयोग तालिका में रिकॉर्ड हटाने के लिए किया जाता है।
- SELECT कथन का उपयोग एक या अधिक डेटाबेस तालिकाओं से डेटा पुनःप्राप्त करने के लिए किया जाता है।
- SELECT * FROM table_name उस तालिका के सभी गुणों से डेटा प्रदर्शित करता है।
- WHERE खंड किसी क्वेरी में शर्त(ओं) को लागू करने के लिए उपयोग किया जाता है।
- DISTINCT खंड दोहराव को समाप्त करता है और मानों को केवल एक बार प्रदर्शित करता है।
- BETWEEN ऑपरेटर सीमा मानों सहित मानों की सीमा को परिभाषित करता है।
- IN ऑपरेटर उन मानों को चुनता है जो दिए गए मानों की सूची में किसी भी मान से मेल खाते हैं।
- NULL मानों की जाँच IS NULL और IS NOT NULL का उपयोग करके की जा सकती है।
- ORDER BY खंड किसी SQL क्वेरी के परिणाम को निर्दिष्ट गुण मानों के संबंध में आरोही या अवरोही क्रम में प्रदर्शित करने के लिए उपयोग किया जाता है। डिफ़ॉल्ट आरोही क्रम है।
- LIKE खंड पैटर्न मिलान के लिए उपयोग किया जाता है। % और _ दो वाइल्डकार्ड वर्ण हैं। प्रतिशत (%) प्रतीक शून्य या अधिक वर्णों को दर्शाने के लिए उपयोग किया जाता है। अंडरस्कोर (_) प्रतील एक एकल वर्ण को दर्शाने के लिए उपयोग किया जाता है।
अभ्यास
1. निम्नलिखित खंडों (clauses) को उनके संगत कार्यों से मिलान कीजिए।
| ALTER | किसी सारणी में मान सम्मिलित करना |
|---|---|
| UPDATE | स्तंभों पर प्रतिबंध |
| DELETE | सारणी परिभाषा |
| INSERT INTO | किसी स्तंभ का नाम बदलना |
| CONSTRAINTS | सारणी में पहले से मौजूद जानकारी को अद्यतन करना |
| DESC | सारणी से पहले से मौजूद पंक्ति को हटाना |
| CREATE | डेटाबेस बनाना |
2. निम्नलिखित कोड अंश के सन्दर्भ में उपयुक्त उत्तर चुनिए।
CREATE TABLE student ( student_id INT, gender CHAR(1), PRIMARY KEY (student_id) $1 ;$ a) student सारणी की घात (degree) क्या होगी?
CREATE TABLE student (
$\qquad$ name CHAR(30),
$\qquad$ student_id INT,
$\qquad$ gender CHAR(1),
$\qquad$ PRIMARY KEY (student_id)
);
a) student सारणी की घात क्या होगी?
i) 30
ii) 1
iii) 3
iv) 4
b) उपरोक्त कोड अंश में ’name’ क्या दर्शाता है?
i) एक सारणी
ii) एक पंक्ति
iii) एक स्तंभ
iv) एक डेटाबेस
c) निम्नलिखित SQL कथन के बारे में क्या सही है?
SelecT * fROM student;
i) ‘student’ सारणी की सामग्री प्रदर्शित करता है
ii) ‘student’ सारणी के स्तंभ नाम और सामग्री प्रदर्शित करता है
iii) गलत केस प्रयोग होने के कारण त्रुटि उत्पन्न करता है
iv) केवल ‘student’ सारणी के स्तंभ नाम प्रदर्शित करता है
d) निम्नलिखित क्वेरी का आउटपुट क्या होगा?
INSERT INTO student
VALUES (“Suhana”, 109,‘F’),
VALUES (“Rivaan”,102,‘M’),
VALUES (“Atharv”,103,‘M’),
VALUES (“Rishika”,105,‘F’),
VALUES (“Garvit”,104,‘M’),
VALUES (“Shaurya”,109,‘M’);
i) त्रुटि
ii) कोई त्रुटि नहीं
iii) कंपाइलर पर निर्भर करता है
iv) क्वेरी का सफल समापन
e) निम्नलिखित क्वेरी में कितनी पंक्तियाँ हटाई जाएँगी?
DELETE student
WHERE student_id=109;
i) 1 पंक्ति
ii) सभी पंक्तियाँ जहाँ student ID 109 के बराबर है
iii) कोई पंक्ति नहीं हटाई जाएगी
iv) 2 पंक्तियाँ
3. रिक्त स्थान भरें:
a) _______ यह घोषित करता है कि एक तालिका में इंडेक्स दूसरी तालिका में इंडेक्स से संबंधित है। $
i) प्राइमरी की
ii) फॉरेन की
iii) कंपोज़िट की
iv) सेकेंडरी की
b) SELECT क्वेरी में एस्टरिक (*) चिह्न ________ प्राप्त करता है।
i) तालिका से सभी डेटा
ii) केवल प्राइमरी की का डेटा
iii) NULL डेटा
iv) उपरोक्त में से कोई नहीं
4. निम्नलिखित MOVIE डेटाबेस पर विचार करें और इसके आधार पर SQL क्वेरीज़ के उत्तर दें।
| MovieID | MovieName | Category | ReleaseDate | ProductionCost | BusinessCost |
|---|---|---|---|---|---|
| 001 | Hindi_Movie | Musical | 2018-04-23 | 124500 | 130000 |
| 002 | Tamil_Movie | Action | 2016-05-17 | 112000 | 118000 |
| 003 | English_Movie | Horror | 2017-08-06 | 245000 | 360000 |
| 004 | Bengali_Movie | Adventure | 2017-01-04 | 72000 | 100000 |
| 005 | Telugu_Movie | Action | - | 100000 | - |
| 006 | Punjabi_Movie | Comedy | - | 30500 | - |
a) फिल्मों की जानकारी उनके कॉलम नामों का उल्लेख किए बिना प्राप्त करें।
b) केवल MovieID, MovieName और BusinessCost दिखाते हुए फिल्मों द्वारा किया गया व्यवसाय सूचीबद्ध करें।
c) फिल्मों की विभिन्न श्रेणियों की सूची बनाएं।
d) प्रत्येक फिल्म का शुद्ध लाभ उसकी ID, नाम और शुद्ध लाभ दिखाते हुए ज्ञात करें।
$($ संकेत: शुद्ध लाभ $=$ व्यवसाय लागत - उत्पादन लागत $)$ यह सुनिश्चित करें कि नए कॉलम का नाम NetProfit रखा गया है। क्या यह कॉलम अब MOVIE संबंध का हिस्सा है? यदि नहीं, तो ऐसे कॉलमों के लिए कौन-सा नाम गढ़ा गया है? आप उस फिल्म के लाभ के बारे में क्या कह सकते हैं जो अभी तक रिलीज़ नहीं हुई है? क्या आपके क्वेरी परिणाम में लाभ शून्य के रूप में दिखाया गया है?
e) सभी फिल्मों की सूची बनाएं जिनकी ProductionCost 80,000 से अधिक और $1,25,000$ से कम है, जिसमें ID, नाम और ProductionCost दिखाएं।
f) सभी फिल्मों की सूची बनाएं जो कॉमेडी या एक्शन श्रेणी में आती हैं।
g) वे फिल्में सूचीबद्ध करें जो अभी तक रिलीज़ नहीं हुई हैं।
5. मान लीजिए आपके स्कूल प्रबंधन ने कक्षा XI और कक्षा XII के छात्रों के बीच क्रिकेट मैच आयोजित करने का निर्णय लिया है। प्रत्येक कक्षा के छात्रों को चार टीमों में से किसी एक में शामिल होने के लिए कहा गया है - टीम टाइटन, टीम रॉकर्स, टीम मैग्नेट और टीम हरिकेन। गर्मियों की छुट्टियों के दौरान इन टीमों के बीच विभिन्न मैच आयोजित किए जाएंगे। अपने खेल शिक्षक की निम्नलिखित कार्यों में सहायता करें:
a) एक डेटाबेस “Sports” बनाएं।
b) निम्नलिखित विचारों के साथ एक तालिका “TEAM” बनाएं:
i) इसमें TeamID नामक एक कॉलम होना चाहिए जो 1 से 9 के बीच का पूर्णांक मान संग्रहीत करे, जो किसी टीम की अद्वितीय पहचान को दर्शाता है।
ii) प्रत्येक TeamID से संबद्ध एक नाम (TeamName) होना चाहिए, जो न्यूनतम 10 वर्णों की एक स्ट्रिंग हो।
c) टेबल-स्तरीय बाधा का उपयोग करके TeamID को प्राइमरी कुंजी बनाएं।
d) SQL कमांड का उपयोग करके TEAM टेबल की संरचना दिखाएं।
e) छात्रों की प्राथमिकताओं के अनुसार नीचे दी गई चार टीमें बनाई गईं। इन चार पंक्तियों को TEAM टेबल में डालें:
पंक्ति 1: (1, Team Titan)
पंक्ति 2: (2, Team Rockers)
पंक्ति 3: (3, Team Magnet)
पंक्ति 4: (4, Team Hurricane)
f) TEAM टेबल की सामग्री दिखाएं।
g) अब नीचे दी गई एक अन्य टेबल बनाएं। MATCH_DETAILS और दी गई टेबल के अनुसार डेटा डालें। प्रत्येक गुण के लिए उपयुक्त डोमेन और बाधाएँ चुनें।
टेबल: MATCH_DETAILS
| MatchID | MatchDate | FirstTeamID | SecondTeamID | FirstTeamScore | SecondTeamScore |
|---|---|---|---|---|---|
| M1 | 2018-07-17 | 1 | 2 | 90 | 86 |
| M2 | 2018-07-18 | 3 | 4 | 45 | 48 |
| M3 | 2018-07-19 | 1 | 3 | 78 | 56 |
| M4 | 2018-07-19 | 2 | 4 | 56 | 67 |
| M5 | 2018-07-20 | 1 | 4 | 32 | 87 |
| M6 | 2018-07-21 | 2 | 3 | 67 | 51 |
h) $\mathrm{MATCH}_{-}$DETAILS टेबल में विदेशी कुंजी बाधा का उपयोग करें जो TEAM टेबल को संदर्भित करे ताकि MATCH_DETAILS टेबल में केवल उन्हीं टीमों के स्कोर दर्ज हों जो TEAM टेबल में मौजूद हैं।
6. दो संबंधों (TEAM, MATCH_DETAILS) वाले स्पोर्ट्स डेटाबेस का उपयोग करते हुए निम्नलिखित संबंधीय बीजगणितीय क्वेरीज़ के उत्तर दें।
क) उन सभी मैचों का MatchID प्राप्त करें जहाँ दोनों टीमों ने 70 से अधिक रन बनाए हैं।
ख) उन सभी मैचों का MatchID प्राप्त करें जहाँ FirstTeam ने 70 से कम रन बनाए हैं लेकिन SecondTeam ने 70 से अधिक रन बनाए हैं।
ग) उन मैचों का MatchID और तारीख ज्ञात करें जो Team 1 ने खेले और जीते।
घ) उन मैचों का MatchID ज्ञात करें जो Team 2 ने खेले लेकिन नहीं जीते।
ङ) TEAM संबंध में संबंध का नाम T_DATA में बदलें। साथ ही TeamID और TeamName गुणों को क्रमशः T_ID और T_NAME में बदलें।
7. निम्नलिखित आदेशों के बीच अंतर बताएं:
क) ALTER और UPDATE
ख) DELETE और DROP
8. STUDENT_PROJECT नामक एक डेटाबेस बनाएं जिसमें निम्नलिखित तालिकाएं हों। उपयुक्त डेटा प्रकार चुनें और आवश्यक बाधाएं लगाएं।
तालिका: STUDENT
| RollNo | Name | Stream | Section | RegistrationID |
|---|
- Stream कॉलम में मान Science, Commerce, या Humanities हो सकते हैं।
- Section कॉलम में मान I या II हो सकते हैं।
तालिका: PROJECT_ASSIGNED
तालिका: PROJECT
| ProjectID | ProjectName | SubmissionDate | TeamSize | GuideTeacher |
|---|
a) इन तालिकाओं में उपयुक्त डेटा भरें।
b) निम्नलिखित के लिए SQL क्वेरीज़ लिखें।
c) विज्ञान स्ट्रीम के छात्रों के नाम खोजें।
d) तीनों तालिकाओं की प्राइमरी कुंजियाँ क्या होंगी?
e) तीनों संबंधों की फॉरेन कुंजियाँ क्या हैं?
f) उन सभी छात्रों के नाम खोजें जो ‘Commerce stream’ कक्षा में पढ़ रहे हैं और एक ही शिक्षक द्वारा मार्गदर्शित हैं, भले ही उन्हें अलग-अलग प्रोजेक्ट सौंपे गए हों।
9. एक संगठन $A B C$ अपने कर्मचारियों और उनके आश्रितों के बारे में निम्नलिखित विवरण रिकॉर्ड करने के लिए एक डेटाबेस EMP. DEPENDENT बनाए रखता है।
Employee(AadhaarNo, Name, Address, Department, Emp| D)
DEPENDENT (EmpI D, DependentName, Rel ationship)
निम्नलिखित SQL क्वेरीज़ का उत्तर देने के लिए EMP - DEPENDENT डेटाबेस का उपयोग करें:
a) उन कर्मचारियों के नाम उनके आश्रितों के नामों के साथ खोजें।
b) किसी विभाग, मान लीजिए ‘PRODUCTION’ में कार्यरत कर्मचारी का विवरण खोजें।
c) उन कर्मचारियों के नाम खोजें जिनका कोई आश्रित नहीं है
d) उन कर्मचारियों के नाम खोजें जो किसी विभाग, मान लीजिए ‘SALES’ में कार्यरत हैं और जिनके ठीक दो आश्रित हैं।
10. एक दुकान जिसका नाम Wonderful Garments है और जो स्कूल यूनिफॉर्म बेचती है, एक डेटाबेस SCHOOL_UNIFORM बनाए रखती है। इसमें दो संबंध शामिल हैं — UNIFORM और PRICE। उन्होंने UNIFORM संबंध के लिए UniformCode को प्राइमरी कुंजी बनाया। इसके अतिरिक्त, उन्होंने PRICE संबंध के लिए UniformCode और Size को समग्र कुंजी के रूप में उपयोग किया। डेटाबेस स्कीमा और डेटाबेस स्थिति का विश्लेषण करके, निम्नलिखित विसंगतियों को दूर करने के लिए SQL क्वेरीज़ निर्दिष्ट करें।
a) PRICE संबंध में Price नामक एक गुण है। भ्रम से बचने के लिए, PRICE संबंध का नाम बदलकर COST करने के लिए SQL क्वेरी लिखें।
UNIFORM
| UCode | UName | UColor |
|---|---|---|
| 1 | Shirt | White |
| 2 | Pant | Grey |
| 3 | Skirt | Grey |
| 4 | Tie | Blue |
| 5 | Socks | Blue |
| 6 | Belt | Blue |
PRICE
| UCode | Size | Price |
|---|---|---|
| 1 | M | 500 |
| 1 | L | 580 |
| 1 | XL | 620 |
| 2 | M | 810 |
| 2 | L | 890 |
| 2 | XL | 940 |
| 3 | M | 770 |
| 3 | L | 830 |
| 3 | XL | 910 |
| 4 | S | 150 |
| 4 | L | 170 |
| 5 | S | 180 |
| 5 | L | 210 |
| 6 | M | 110 |
| 6 | L | 140 |
| 6 | XL | 160 |
b) M/S Wonderful Garments के पास लाल रंग के, मीडियम साइज़ के ₹100 प्रति नक़द रुमाल भी हैं। इस रिकॉर्ड को COST तालिका में डालें।
c) जब आपने उपरोक्त क्वेरी का उपयोग कर डेटा डाला, तो आप UNIFORM संबंध में उसका विवरण दर्ज किए बिना ही रुमाल के मान दर्ज कर सके। ऐसी व्यवस्था बनाएँ कि COST तालिका में डेटा तभी दर्ज हो सके जब वह पहले से UNIFORM तालिका में मौजूद हो।
d) आगे, आप किसी वस्तु को नया UCode तभी दे सकें जब उसका मान्य UName हो। SCHOOL UNIFORM डेटाबेस में उपयुक्त बाधा जोड़ने के लिए क्वेरी लिखें।
e) ALTER table का उपयोग कर यह बाधा जोड़ें कि किसी वस्तु की कीमत हमेशा शून्य से अधिक हो।



